
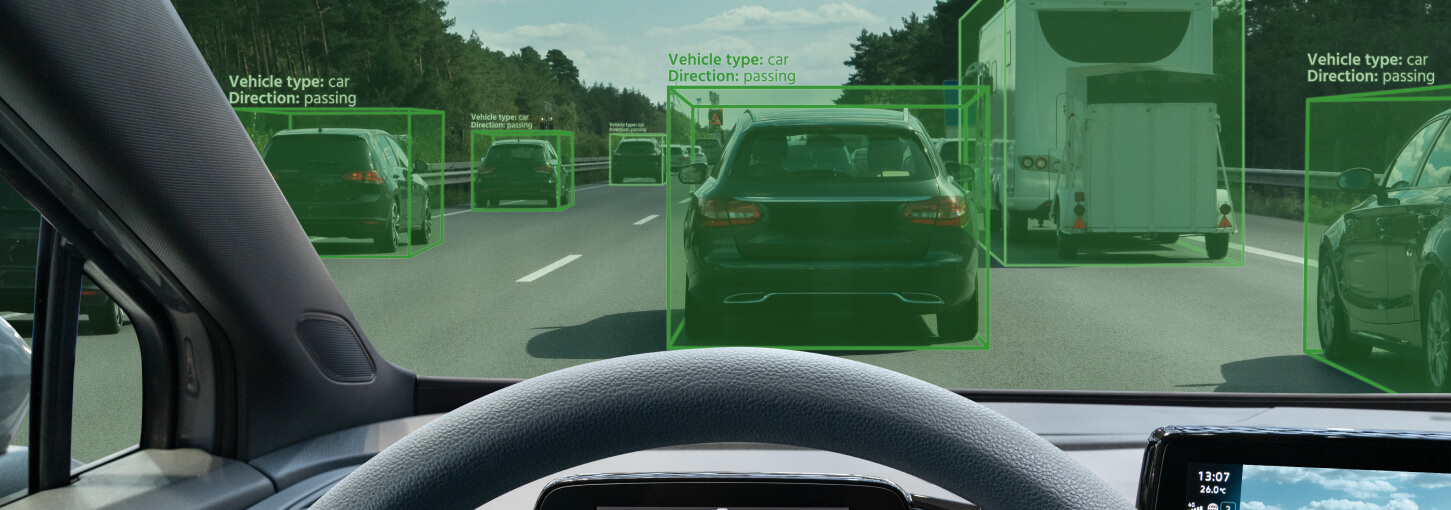
Computer Vision Services
NextWealth delivers Computer Vision Services for Autonomous Vehicles, Medical AI, Geospatial Tech, and Retail by enriching, annotating, and labeling image and video data for AI and Machine Learning models.
We are experts in various types of annotation like

Bounding Box
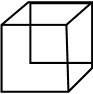
Cuboid
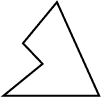
Polygon
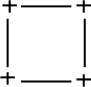
Keypoint

Instance Segmentation

Polyline

Semantic segmentation
Use cases:
- Robotics
- Autonomous vehicles
- Food harvesting
- Surveillance
- Inventory control

Use cases:
- Shopper behavior
- Surveillance
- Sports analytics
- Traffic control
- Autonomous vehicles

Use cases:
- Visual search
- Product recommendations
- Telemedicine
- Law enforcement

Use cases:
- Autonomous vehicles
- Aerial surveying
- Surveillance
- Robotic navigation
- Law enforcement
- Livestock management

Our areas of expertise

Data Detection
Use cases:
- Robotics
- Autonomous vehicles
- Food harvesting
- Surveillance
- Inventory control
Data tracking
Use cases:
- Shopper behavior
- Surveillance
- Sports analytics
- Traffic control
- Autonomous vehicles


classification
Use cases:
- Visual search
- Product recommendations
- Telemedicine
- Law enforcement
Segmentation
Use cases:
- Autonomous vehicles
- Aerial surveying
- Surveillance
- Robotic navigation
- Law enforcement
- Livestock management




I am really happy at all the great things we have been able to achieve in the past 1 year. The relationship now has a solid foundation, and I am sure NextWealth will continue to be a formidable partner going ahead, bringing a delightful experience for our customers.
NextWealth has been an invaluable partner to us, significantly accelerating our growth by handling critical data operations and providing strategic insights.
NextWealth’s hard work and dedication are truly making a difference, streamlining our processes significantly. We really appreciate it!
My experience with NextWealth has been wonderful. The diligent team consistently delivers on time with a focus on quality. Their innovation-driven mindset fosters a win-win situation for both teams.
I am happy with the improvement in the performance. I have seen positive improvement, and we have a long way to go.
NextWealth’s in-depth analysis helped us pinpoint exactly what needs to be done to address the issues.
With excellence in Quality, Cost, and TAT—key pillars of any operation—NextWealth sets a benchmark for operational efficiency and beyond.
We have experienced significant growth—a success we could not have achieved without the expert support, hard work, and commitment of NextWealth.

RLHF for Enterprise LLMs: Services, Costs, and How to Choose the Right Partner
1 min read

Enterprise Data Annotation in 2025: Platforms, Pipelines, and Getting Both Right
1 min read
Latest Update

Best Data Annotation Companies for AI Training in 2025–26: The Complete Buyer’s Guide
1 min read